复合查询使您能够组合现有查询中的数据,然后在显示报告结果之前应用过滤器,聚合等,这些结果显示组合数据集. Composite Query检索现有查询的多个级别的相关信息,并将组合数据显示为单个平展查询结果.
使用Composite Query,您还可以选择 :
选择SQL修剪选项,根据用户的属性选择删除不需要的表和字段.
设置ORDER BY和GROUP BY子句.
将WHERE子句设置为结果集上的过滤器复合查询.
可以组合上述运算符以形成更强大的查询.由于DocumentDB支持嵌套集合,因此组合可以连接或嵌套.
让我们考虑本例中的以下文档.
AndersenFamily 文件如下.
{ "id": "AndersenFamily", "lastName": "Andersen", "parents": [ { "firstName": "Thomas", "relationship": "father" }, { "firstName": "Mary Kay", "relationship": "mother" } ], "children": [ { "firstName": "Henriette Thaulow", "gender": "female", "grade": 5, "pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ] } ], "location": { "state": "WA", "county": "King", "city": "Seattle" }, "isRegistered": true }SmithFamily 文件如下.
{ "id": "SmithFamily", "parents": [ { "familyName": "Smith", "givenName": "James" }, { "familyName": "Curtis", "givenName": "Helen" } ], "children": [ { "givenName": "Michelle", "gender": "female", "grade": 1 }, { "givenName": "John", "gender": "male", "grade": 7, "pets": [ { "givenName": "Tweetie", "type": "Bird" } ] } ], "location": { "state": "NY", "county": "Queens", "city": "Forest Hills" }, "isRegistered": true }WakefieldFamily 文件如下.
{ "id": "WakefieldFamily", "parents": [ { "familyName": "Wakefield", "givenName": "Robin" }, { "familyName": "Miller", "givenName": "Ben" } ], "children": [ { "familyName": "Merriam", "givenName": "Jesse", "gender": "female", "grade": 6, "pets": [ { "givenName": "Charlie Brown", "type": "Dog" }, { "givenName": "Tiger", "type": "Cat" }, { "givenName": "Princess", "type": "Cat" } ] }, { "familyName": "Miller", "givenName": "Lisa", "gender": "female", "grade": 3, "pets": [ { "givenName": "Jake", "type": "Snake" } ] } ], "location": { "state": "NY", "county": "Manhattan", "city": "NY" }, "isRegistered": false }我们来吧看一下连接查询的例子.
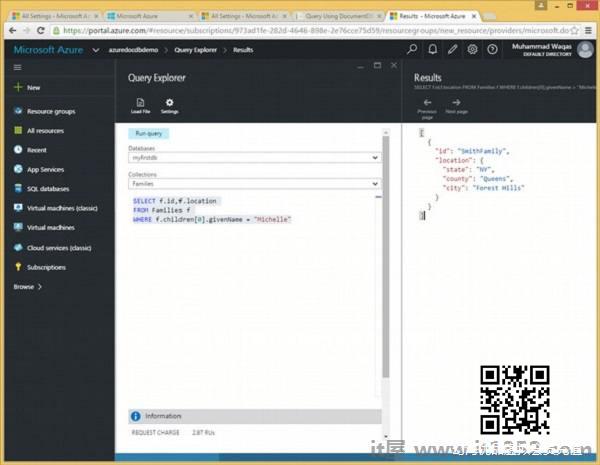
以下是查询将检索第一个孩子 givenName 为Michelle的家庭的ID和位置.
SELECT f.id,f.location FROM Families f WHERE f.children[0].givenName = "Michelle"
执行上述查询时,它会产生以下输出.
[ { "id": "SmithFamily", "location": { "state": "NY", "county": "Queens", "city": "Forest Hills" } }]让我们考虑连接查询的另一个例子.
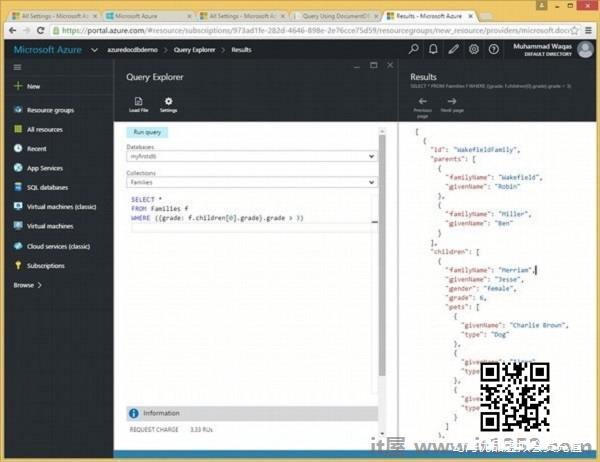
以下是查询y将返回第一个孩子等级大于3的所有文件.
SELECT * FROM Families f WHERE ({grade: f.children[0].grade}.grade > 3)执行上述查询时,会产生以下输出.
[ { "id": "WakefieldFamily", "parents": [ { "familyName": "Wakefield", "givenName": "Robin" }, { "familyName": "Miller", "givenName": "Ben" } ], "children": [ { "familyName": "Merriam", "givenName": "Jesse", "gender": "female", "grade": 6, "pets": [ { "givenName": "Charlie Brown", "type": "Dog" }, { "givenName": "Tiger", "type": "Cat" }, { "givenName": "Princess", "type": "Cat" } ] }, { "familyName": "Miller", "givenName": "Lisa", "gender": "female", "grade": 3, "pets": [ { "givenName": "Jake", "type": "Snake" } ] } ], "location": { "state": "NY", "county": "Manhattan", "city": "NY" }, "isRegistered": false, "_rid": "Ic8LAJFujgECAAAAAAAAAA==", "_ts": 1450541623, "_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgECAAAAAAAAAA==/", "_etag": "00000500-0000-0000-0000-567582370000", "_attachments": "attachments/" }, { "id": "AndersenFamily", "lastName": "Andersen", "parents": [ { "firstName": "Thomas", "relationship": "father" }, { "firstName": "Mary Kay", "relationship": "mother" } ], "children": [ { "firstName": "Henriette Thaulow", "gender": "female", "grade": 5, "pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ] } ], "location": { "state": "WA", "county": "King", "city": "Seattle" }, "isRegistered": true, "_rid": "Ic8LAJFujgEEAAAAAAAAAA==", "_ts": 1450541624, "_self": "dbs/Ic8LAA==/colls/Ic8LAJFujgE=/docs/Ic8LAJFujgEEAAAAAAAAAA==/", "_etag": "00000700-0000-0000-0000-567582380000", "_attachments": "attachments/" } ]我们来看看看看嵌套查询的示例.
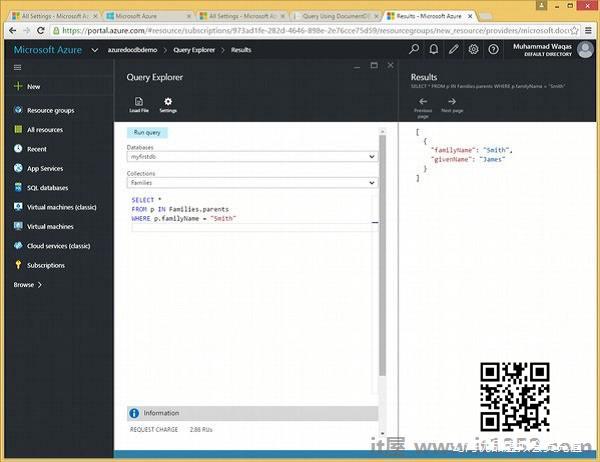
以下是查询将迭代所有父项,然后返回 familyName 为Smith的文档.
SELECT * FROM p IN Families.parents WHERE p.familyName = "Smith"
当abov执行e查询,它会产生以下输出.
[ { "familyName": "Smith", "givenName": "James" } ]让我们考虑另一个例子嵌套查询.
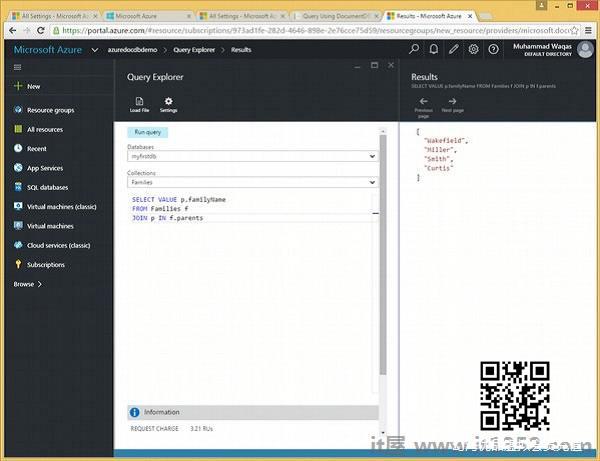
以下是查询返回所有 familyName .
SELECT VALUE p.familyNameFROM Families f JOIN p IN f.parents
执行上述查询时,会产生以下输出.
[ "Wakefield", "Miller", "Smith", "Curtis" ]