在本章中,我们将学习如何开始使用Natural Language Toolkit Package.
先决条件
如果我们想构建应用程序使用自然语言处理,然后上下文的变化使其变得最困难.上下文因素影响机器理解特定句子的方式.因此,我们需要使用机器学习方法开发自然语言应用程序,以便机器也能理解人类理解上下文的方式.
要构建这样的应用程序,我们将使用Python包称为NLTK(自然语言工具包).
导入NLTK
我们需要在使用之前安装NLTK.它可以在以下命令的帮助下安装 :
pip install nltk
要为NLTK构建conda包,请使用以下命令 :
conda install -c anaconda nltk
现在安装NLTK软件包后,我们需要通过python命令提示符导入它.我们可以通过在Python命令提示符上写下以下命令来导入它;<
>>> import nltk
下载NLTK的数据
现在导入NLTK后,我们需要下载所需的数据.它可以在Python命令提示符下使用以下命令来完成 :
>>> nltk.download()
安装其他必要软件包
要使用NLTK构建自然语言处理应用程序,我们需要安装必要的包.这些软件包如下:<
gensim
它是一个强大的语义建模库,对许多应用程序都很有用.我们可以通过执行以下命令来安装它 :
pip install gensim
pattern
用于使 gensim 包正常工作.我们可以通过执行以下命令来安装它
pip install pattern
标记化,词干化和词形还原的概念
在本节中,我们将理解什么是标记化,词干化和词形还原.
标记化h3>
它可以被定义为将给定文本(即字符序列)分解为称为标记的较小单元的过程.标记可以是单词,数字或标点符号.它也被称为分词.以下是标记化的简单示例 :
输入 : 芒果,香蕉,菠萝和苹果都是水果.
输出 : 
打破给定文本的过程可以在定位的帮助下完成单词边界.单词的结尾和新单词的开头称为单词边界.写作系统和单词的印刷结构影响边界.
在Python NLTK模块中,我们有与标记化相关的不同包,我们可以使用这些包将文本分成标记.我们的要求.一些软件包如下:<
sent_tokenize package
顾名思义,这个软件包会将输入文本分成句子.我们可以借助以下Python代码导入此包并减去;
from nltk.tokenize import sent_tokenize
word_tokenize package
此包将输入文本分为单词.我们可以借助以下Python代码导入此包并减去;
from nltk.tokenize import word_tokenize
WordPunctTokenizer包
此包将输入文本分为单词和标点符号.我们可以借助以下Python代码导入此包并减去;
from nltk.tokenize import WordPuncttokenizer
词干
在处理单词时,由于语法原因,我们遇到了很多变化.这里的变体概念意味着我们必须处理不同形式的相同词语,如 民主,民主, 和 民主化 的.机器非常有必要理解这些不同的单词具有相同的基本形式.通过这种方式,在分析文本时提取单词的基本形式会很有用.
我们可以通过词干来实现.通过这种方式,我们可以说词干是通过切断单词末尾来提取单词的基本形式的启发式过程.
在Python NLTK模块中,我们有不同的包与干预有关.这些包可用于获取单词的基本形式.这些包使用算法.一些软件包如下:<
PorterStemmer软件包
这个Python软件包使用Porter的算法来提取基本形式.我们可以借助以下Python代码导入此包并减去;
from nltk.stem.porter import PorterStemmer
例如,如果我们将单词'写'作为此词干分析器的输入,我们将得到单词'write'<词干之后.
LancasterStemmer包
这个Python包将使用Lancaster的算法来提取基本形式.我们可以借助以下Python代码导入此包并减去;
from nltk.stem.lancaster import LancasterStemmer
例如,如果我们将单词'写'作为此词干分析器的输入,我们将得到单词'write'在阻止之后.
SnowballStemmer包
这个Python包将使用雪球的算法来提取基本形式.我们可以借助以下Python代码导入此软件包 :
from nltk.stem.snowball import SnowballStemmer
例如,如果我们将单词'写'作为此词干分析器的输入,我们将得到单词'write'在词干之后.
所有这些算法都有不同的严格程度.如果我们比较这三个词干分析器,那么Porter词干分析器是最不严格的,Lancaster是最严格的.雪球词干器在速度和严格性方面都很好用.
词形还原
我们还可以通过词形还原来提取单词的基本形式.它基本上通过词汇和词汇的形态分析来完成这项任务,通常只是为了消除屈折结局.任何单词的这种基本形式称为引理.
词干和词形化之间的主要区别在于词汇的使用和词汇的形态分析.另一个不同之处在于,词典最常折叠衍生相关词,而词形词化通常只会折叠引理的不同屈折形式.例如,如果我们提供单词saw作为输入单词,那么词干可能会返回单词's',但是词形还原会尝试返回单词see或saw,具体取决于令牌的使用是动词还是名词./p>
在Python NLTK模块中,我们有以下与词形还原过程相关的包,我们可以使用它来获得word&minus的基本形式;
WordNetLemmatizer package
这个Python包将根据它是用作名词还是用作动词来提取单词的基本形式.我们可以借助以下Python代码导入此包并减去;
from nltk.stem import WordNetLemmatizer
分块:将数据分成块?
这是自然语言处理中的重要过程之一.分块的主要工作是识别词性和短语,如名词短语.我们已经研究了令牌化的过程,即令牌的创建. Chunking基本上是那些令牌的标签.换句话说,分块将向我们显示句子的结构.
在下一节中,我们将了解不同类型的分块.
分块类型
有两种类型的分块.类型如下 :
分块上升
在这个分块过程中,对象,事物等变得更加通用语言变得更抽象.达成协议的可能性更大.在这个过程中,我们缩小.例如,如果我们将问题"为什么汽车是什么"?我们可能会得到答案"传输".
分块下来
在这个分块过程中,对象,事物等变得越来越多特定的和语言得到更深入的渗透.更深层次的结构将在分块中进行检查.在这个过程中,我们放大.例如,如果我们把问题"特意讲述一辆汽车"?我们将获得有关该车的较小信息.
示例
在此示例中,我们将执行Noun-短语分块,一种分块类型,它将在句子中找到名词短语块,使用Python中的NLTK模块 :
在python中执行这些步骤以实现名词短语chunking :
第1步 : 在这一步中,我们需要定义分块的语法.它将包含我们需要遵循的规则.
第2步 : 在这一步中,我们需要创建一个块解析器.它会解析语法并给出输出.
第3步 : 在最后一步中,输出以树格式生成.
让我们导入必要的NLTK包,如下所示;
import nltk
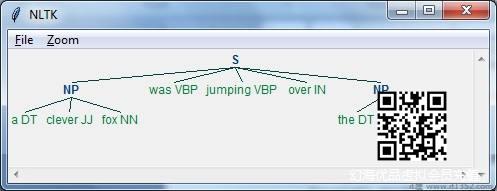
现在,我们需要定义句子.这里,DT表示行列式,VBP表示动词,JJ表示形容词,IN表示介词,NN表示名词.
sentence=[("a","DT"),("clever","JJ"),("fox","NN"),("was","VBP"), ("jumping","VBP"),("over","IN"),("the","DT"),("wall","NN")]现在,我们需要给出语法.在这里,我们将以正则表达式的形式给出语法.
grammar = "NP:{我们需要定义一个解析语法的解析器.
parser_chunking = nltk.RegexpParser(grammar)
解析器解析句子如下 :
parser_chunking.parse(sentence)
接下来,我们需要获取输出.输出在名为 output_chunk 的简单变量中生成.
Output_chunk = parser_chunking.parse(sentence)
执行以下代码后,我们可以以树的形式绘制输出.
output.draw()
Bag of Word(BoW)模型
Bag of Word(BoW),一种自然语言处理模型,主要用于从文本中提取特征,以便文本可以用于建模,以便在机器学习算法中使用.
现在出现的问题是为什么我们需要从文本中提取特征.这是因为机器学习算法不能处理原始数据,它们需要数字数据,以便它们可以从中提取有意义的信息.将文本数据转换为数字数据称为特征提取或特征编码.
工作原理
这是提取特征的非常简单的方法来自文字.假设我们有一个文本文档,我们想将其转换为数字数据,或者想要从中提取特征,那么首先该模型从文档中的所有单词中提取词汇表.然后通过使用文档术语矩阵,它将构建一个模型.通过这种方式,BoW仅将文档表示为一个单词包.关于文档中单词的顺序或结构的任何信息都将被丢弃.
文档术语矩阵的概念
BoW算法通过使用构建模型文件术语矩阵.顾名思义,文档术语矩阵是文档中出现的各种字数的矩阵.在该矩阵的帮助下,文本文档可以表示为各种单词的加权组合.通过设置阈值并选择更有意义的单词,我们可以构建文档中可用作特征向量的所有单词的直方图.以下是理解文档术语矩阵和减号概念的示例;
示例
假设我们有以下两个句子&减去;
现在,通过考虑这两个句子,我们有以下13个不同的单词&minus ;
we
are
using
the
bag
of
words
model
is
used
for
extracting
features
现在,我们需要为每个句子构建一个直方图在每个句子中使用单词count :
句子1 : [1,1,1,1,1,1,1,1,0,0,0,0,0]
句子2 : [0,0,0,1,1,1,1,1,1,1,1,1,1]
通过这种方式,我们得到了已经提取的特征向量.每个特征向量都是13维的,因为我们有13个不同的单词.
统计的概念
统计的概念称为TermFrequency-Inverse文件频率(tf-idf).每个字在文档中都很重要.统计数据有助于我们理解每个单词的重要性.
期限频率(tf)
它衡量每个单词出现的频率文献.可以通过将每个单词的计数除以给定文档中的单词总数来获得.
反向文档频率(idf)
它衡量一个单词在给定文档集中对该文档的唯一性.为了计算idf并制定一个与众不同的特征向量,我们需要减少常见词汇的权重,并对稀有词汇进行权衡.
在NLTK中建立一个单词模型
h2>
在本节中,我们将使用CountVectorizer从这些句子中创建向量来定义字符串集合.
让我们导入必要的包 :
from sklearn.feature_extraction.text import CountVectorizer
现在定义集合句子.
Sentences = ['We are using the Bag of Word model', 'Bag of Word model is used for extracting the features.']vectorizer_count = CountVectorizer()features_text = vectorizer.fit_transform(Sentences).todense()print(vectorizer.vocabulary_)
上述程序生成输出,如下所示.它表明我们在上面的两个句子中有13个不同的单词 :
{'we': 11, 'are': 0, 'using': 10, 'the': 8, 'bag': 1, 'of': 7, 'word': 12, 'model': 6, 'is': 5, 'used': 9, 'for': 4, 'extracting': 2, 'features': 3}这些是特征向量(文本到数字形式),它可以用于机器学习.
解决问题
在本节中,我们将解决一些相关问题.
类别预测
在一组文件中,不仅单词而且单词的类别也很重要;特定单词属于哪种类型的文本.例如,我们想要预测给定句子是否属于电子邮件,新闻,体育,计算机等类别.在下面的示例中,我们将使用tf-idf来制定特征向量以查找文档类别.我们将使用sklearn的20个新闻组数据集中的数据.
我们需要导入必要的包 :
from sklearn.datasets import fetch_20newsgroupsfrom sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
定义类别图.我们使用了五个不同的类别,名为Religion,Autos,Sports,Electronics和Space.
category_map = {'talk.religion.misc':'Religion','rec.autos''Autos', 'rec.sport.hockey':'Hockey','sci.electronics':'Electronics', 'sci.space': 'Space'}创建训练集 :
training_data = fetch_20newsgroups(subset = 'train', categories = category_map.keys(), shuffle = True, random_state = 5)
构建计数向量化并提取术语计数 :
vectorizer_count = CountVectorizer()train_tc = vectorizer_count.fit_transform(training_data.data)
print("\nDimensions of training data:", train_tc.shape)
tf-idf变换器创建如下 :
tfidf = TfidfTransformer()train_tfidf = tfidf.fit_transform(train_tc)
现在,定义测试数据 :
input_data = [ 'Discovery was a space shuttle', 'Hindu, Christian, Sikh all are religions', 'We must have to drive safely', 'Puck is a disk made of rubber', 'Television, Microwave, Refrigrated all uses electricity']
以上数据将帮助我们训练多项式朴素贝叶斯分类器 :
classifier = MultinomialNB().fit(train_tfidf, training_data.target)
使用计数向量化器转换输入数据 :
input_tc = vectorizer_count.transform(input_data)
现在,我们将使用tfidf转换矢量化数据变压器 :
input_tfidf = tfidf.transform(input_tc)
我们将预测输出类别 :
predictions = classifier.predict(input_tfidf)输出生成如下 :
for sent, category in zip(input_data, predictions): print('\nInput Data:', sent, '\n Category:', \ category_map[training_data.target_names[category]])类别预测器生成以下输出 :
Dimensions of training data: (2755, 39297)Input Data: Discovery was a space shuttleCategory: SpaceInput Data: Hindu, Christian, Sikh all are religionsCategory: ReligionInput Data: We must have to drive safelyCategory: AutosInput Data: Puck is a disk made of rubberCategory: HockeyInput Data: Television, Microwave, Refrigrated all uses electricityCategory: Electronics
性别查找器
在此问题陈述中,将通过提供名称来训练分类器以查找性别(男性或女性).我们需要使用启发式来构造特征向量并训练分类器.我们将使用scikit-learn包中的标记数据.以下是构建性别查找器的Python代码 :
让我们导入必要的包 :
import randomfrom nltk import NaiveBayesClassifierfrom nltk.classify import accuracy as nltk_accuracyfrom nltk.corpus import names
现在我们需要从输入字中提取最后N个字母.这些字母将作为特征和减号;
def extract_features(word, N = 2): last_n_letters = word[-N:] return {'feature': last_n_letters.lower()}if __name__=='__main__':使用NLTK中可用的带标签名称(男性和女性)创建训练数据;
male_list = [(name, 'male') for name in names.words('male.txt')]female_list = [(name, 'female') for name in names.words('female.txt')]data = (male_list + female_list)random.seed(5)random.shuffle(data)现在,测试数据将创建如下 :
namesInput = ['Rajesh', 'Gaurav', 'Swati', 'Shubha']
使用以下代码定义用于训练和测试的样本数
train_sample = int(0.8 * len(data))
现在,我们需要迭代不同的长度,以便精确度可以比较&减去;
for i in range(1, 6): print('\nNumber of end letters:', i) features = [(extract_features(n, i), gender) for (n, gender) in data] train_data, test_data = features[:train_sample],features[train_sample:] classifier = NaiveBayesClassifier.train(train_data)分类器的准确度可以计算如下:<
accuracy_classifier = round(100 * nltk_accuracy(classifier, test_data), 2) print('Accuracy = ' + str(accuracy_classifier) + '%')现在,我们可以预测输出 :
for name in namesInput: print(name, '==>', classifier.classify(extract_features(name, i)))
上述程序将生成以下输出 :
Number of end letters: 1Accuracy = 74.7%Rajesh -> femaleGaurav -> maleSwati -> femaleShubha -> femaleNumber of end letters: 2Accuracy = 78.79%Rajesh -> maleGaurav -> maleSwati -> femaleShubha -> femaleNumber of end letters: 3Accuracy = 77.22%Rajesh -> maleGaurav -> femaleSwati -> femaleShubha -> femaleNumber of end letters: 4Accuracy = 69.98%Rajesh -> femaleGaurav -> femaleSwati -> femaleShubha -> femaleNumber of end letters: 5Accuracy = 64.63%Rajesh -> femaleGaurav -> femaleSwati -> femaleShubha -> female
在上面的输出中,我们可以看到最大结束字母数的准确度是2,并且随着结束字母数量的增加而减少.
主题建模:识别文本数据中的模式
我们知道通常将文档分组到主题中.有时我们需要识别与特定主题相对应的文本中的模式.这样做的技术称为主题建模.换句话说,我们可以说主题建模是一种在给定文档集中发现抽象主题或隐藏结构的技术.
我们可以在以下场景中使用主题建模技术&minus ;
文本分类
在主题建模的帮助下,可以改进分类,因为它将相似的单词组合在一起,而不是单独使用每个单词作为功能.
推荐系统
在主题建模的帮助下,我们可以使用相似性度量来构建推荐系统.
主题建模算法
可以使用算法实现主题建模.算法如下 :
潜在Dirichlet分配(LDA)
此算法是主题建模中最常用的算法.它使用概率图形模型来实现主题建模.我们需要在Python中导入gensim包以使用LDA算法.
潜在语义分析(LDA)或潜在语义索引(LSI)
此算法基于线性代数.基本上它在文档术语矩阵上使用SVD(奇异值分解)的概念.
非负矩阵分解(NMF)
它是同样基于线性代数.
所有上述主题建模算法都将主题数作为参数,文档 - 字矩阵作为输入和 WTM(Word主题矩阵)& TDM(主题文档矩阵)作为输出.