SAP HANA Information Modeler;也称为HANA Data Modeler是HANA系统的核心.它可以在数据库表的顶部创建建模视图,并实现业务逻辑,以创建有意义的分析报告.
Information Modeler的功能
提供存储在HANA数据库物理表中的事务数据的多个视图,以用于分析和业务逻辑目的.
信息建模器仅适用于基于列的存储表.
信息建模视图由基于Java或HTML的应用程序或SAP Lumira或Analysis等SAP工具使用用于报告目的的办公室.
也可以使用MS Excel等第三方工具连接到HANA并创建报告.
SAP HANA建模视图利用SAP HANA的实力.
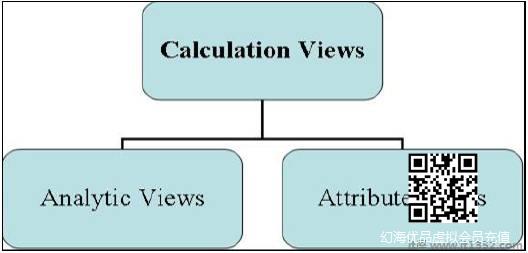
信息视图有三种类型,定义为 :
属性视图
分析视图
计算视图
行与列存储
SAP HANA Modeler视图只能在基于列的表的顶部创建.在Column表中存储数据并不是一件新鲜事.之前假设在基于Columnar的结构中存储数据需要更多的内存大小而不是性能优化.
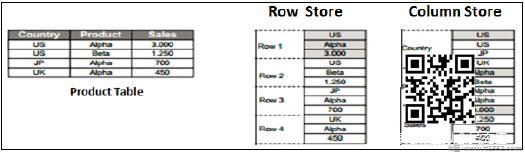
随着SAP HANA的发展,HANA在信息视图中使用了基于列的数据存储,并展示了基于行的表格的柱状表的真正好处.
列存储
在列存储表中,数据垂直存储.因此,类似的数据类型汇集在一起,如上例所示.它借助内存计算引擎提供更快的内存读写操作.
在传统数据库中,数据存储在基于行的结构中,即水平存储. SAP HANA以行和列为基础的结构存储数据.这在HANA数据库中提供了性能优化,灵活性和数据压缩.
在基于列的表中存储数据具有以下优点;
数据压缩
与传统的基于行的存储相比,对表的读写访问速度更快
灵活性&并行处理
以更高的速度执行聚合和计算
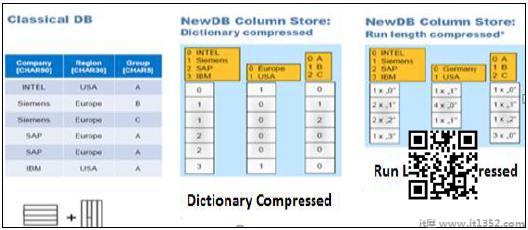
有多种方法和算法可以将数据存储在基于列的结构 - 字典压缩,运行长度压缩等等.
在字典压缩中,单元格以数字的形式存储在表格中与字符相比,数字单元格始终是性能优化的.
在运行长度压缩中,它以数字格式保存带有单元格值的乘数,乘数在表格中显示重复值.
功能差异 - 行与列存储
如果SQL语句必须执行聚合函数和计算,则始终建议使用基于列的存储.基于列的表在运行Sum,Count,Max,Min等聚合函数时总能表现得更好.
当输出必须返回完整行时,首选基于行的存储.下面给出的示例使其易于理解.
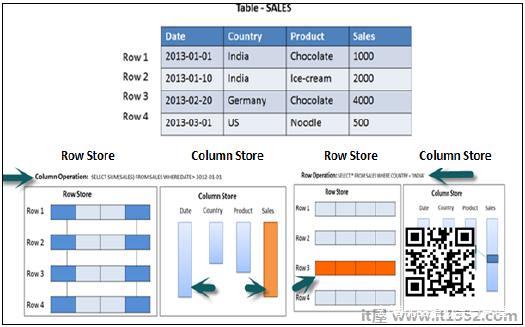
在上面的示例中,在使用Where子句在sales列中运行Aggregate函数(Sum)时,它只会在运行SQL查询时使用Date和Sales列,所以如果它是基于列的存储表,那么它将进行性能优化,更快,因为只需要两列数据.
在运行简单的Select查询时,必须在输出中打印完整行,因此建议在此方案中将表存储为Row.
信息建模视图
属性视图
属性是数据库表中不可测量的元素.它们代表主数据,类似于BW的特征.属性视图是数据库中的维度,或用于在建模中连接维度或其他属性视图.
重要特征是 :
在分析和计算视图中使用属性视图.
属性视图表示主数据.
用于过滤分析和计算视图中维度表的大小.
分析视图
分析视图使用SAP HANA的强大功能对数据库中的表执行计算和聚合功能.它至少有一个事实表,其中包含维度表的度量和主键,并由维度表包含,包含主数据.
重要功能是 :
分析视图用于执行星型模式查询.
分析视图至少包含一个事实表和多个维度表,包含主数据并执行计算和聚合
它们类似于SAP BW中的信息多维数据集和信息对象.
可以在属性视图和事实表之上创建分析视图,并执行计算单位销售数量,总价格等等.
计算视图
计算视图用于分析和属性视图之上,以执行复杂计算,这是分析视图无法实现的.计算视图是基本列表,属性视图和分析视图的组合,用于提供业务逻辑.
重要功能是 :
计算视图使用HANA建模功能进行图形化定义或在SQL中编写脚本.
创建为执行复杂计算,这是其他视图无法实现的 - SAP HANA建模器的属性和分析视图.
使用一个或多个属性视图和分析视图帮助内置函数,如项目,联盟,加入,计算视图中的排名.