在上一章中,我们已经了解了Talend如何使用大数据.在本章中,让我们了解如何使用地图Reduce with Talend.
创建Talend MapReduce作业
让我们学习如何运行MapReduce Talend的工作.在这里,我们将运行MapReduce字数统计示例.
为此,右键单击"作业设计"并创建一个新作业 - MapreduceJob.提及作业的详细信息,然后单击"完成".
向MapReduce作业添加组件
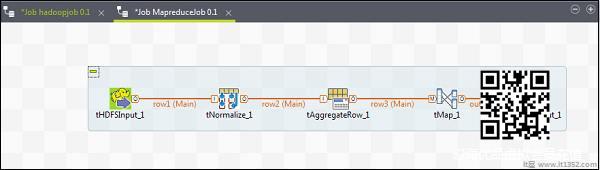
要将组件添加到MapReduce作业,请将Talend的五个组件 - tHDFSInput,tNormalize,tAggregateRow,tMap,tOutput从托盘拖放到设计器窗口.右键单击tHDFSInput并创建指向tNormalize的主链接.
右键单击tNormalize并创建指向tAggregateRow的主链接.然后,右键单击tAggregateRow并创建指向tMap的主链接.现在,右键单击tMap并创建指向tHDFSOutput的主链接.
配置组件和转换
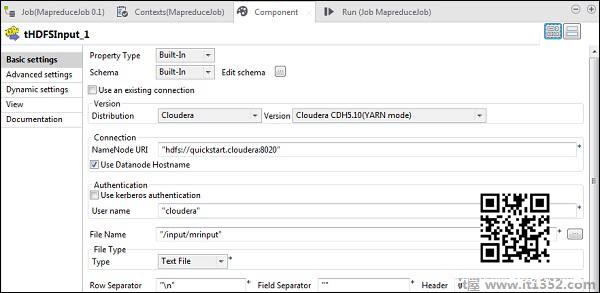
在tHDFSInput中,选择分发cloudera及其版本.请注意,Namenode URI应为"hdfs://quickstart.cloudera:8020",用户名应为"cloudera".在文件名选项中,将输入文件的路径提供给MapReduce作业.确保此输入文件存在于HDFS上.
现在,根据您的输入文件选择文件类型,行分隔符,文件分隔符和标题.
单击编辑架构并将字段"line"添加为字符串类型.
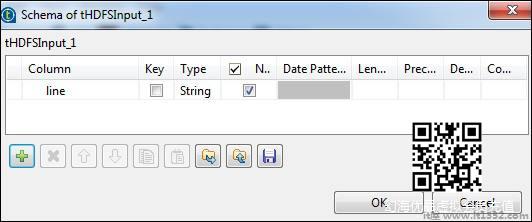
在tNomalize中,要规范化的列将为行,而项目分隔符将为空格 - > "".现在,单击编辑模式. tNormalize将有行列,tAggregateRow将有2列word和wordcount,如下所示.
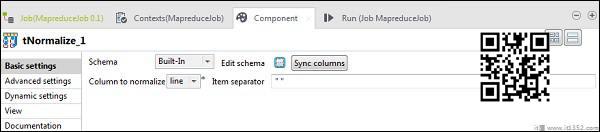

在tAggregateRow中,将word作为输出列放在Group by选项中.在操作中,将wordcount作为输出列,将函数作为计数,将输入列位置作为行.
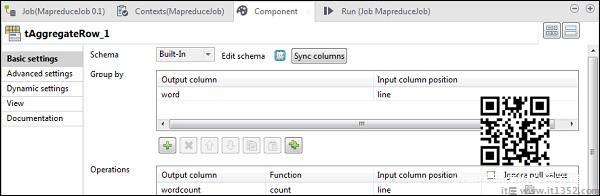
现在双击tMap组件进入地图编辑器并将输入映射到所需的输出.在此示例中,word用word映射,wordcount用wordcount映射.在表达式列中,单击[...]以进入表达式构建器.
现在,从类别列表和UPCASE函数中选择StringHandling.将表达式编辑为"StringHandling.UPCASE(row3.word)",然后单击"确定".将row3.wordcount保存在与wordcount对应的表达式列中,如下所示.
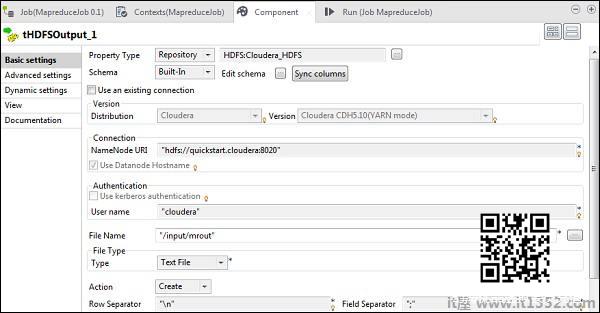
在tHDFSOutput中,连接到我们从属性类型创建的Hadoop集群作为存储库.观察该字段将自动填充.在"文件名"中,指定要存储输出的输出路径.保持Action,行分隔符和字段分隔符如下所示.
执行MapReduce作业
成功完成配置后,单击运行并执行MapReduce作业.
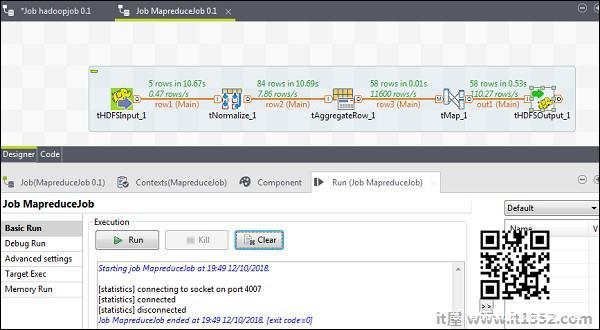
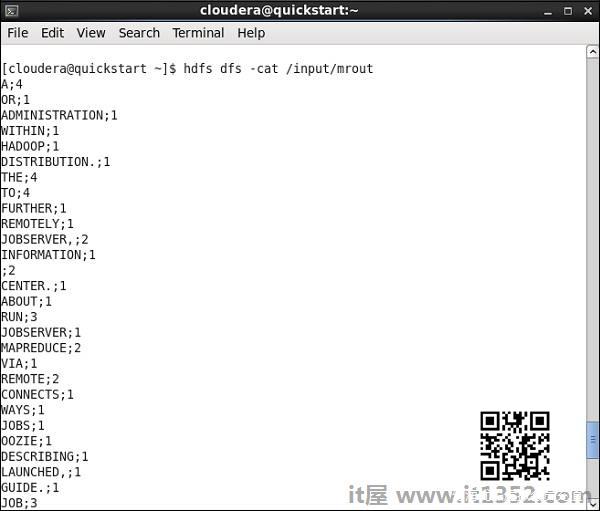
转到HDFS路径并检查输出.请注意,所有单词都将以wordcount大写.