TensorFlow包含图像识别的特殊功能,这些图像存储在特定文件夹中.对于相对相同的图像,出于安全目的,很容易实现此逻辑.
图像识别代码实现的文件夹结构如下所示 :
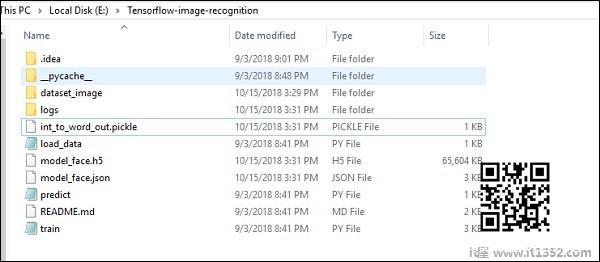
dataset_image包含需要加载的相关图像.我们将专注于图像识别,其中定义了我们的徽标.图像加载了"load_data.py"脚本,这有助于记录其中的各种图像识别模块.
import picklefrom sklearn.model_selection import train_test_splitfrom scipy import miscimport numpy as npimport oslabel = os.listdir("dataset_image")label = label[1:]dataset = []for image_label in label: images = os.listdir("dataset_image/"+image_label) for image in images: img = misc.imread("dataset_image/"+image_label+"/"+image) img = misc.imresize(img, (64, 64)) dataset.append((img,image_label))X = []Y = []for input,image_label in dataset: X.append(input) Y.append(label.index(image_label))X = np.array(X)Y = np.array(Y)X_train,y_train, = X,Ydata_set = (X_train,y_train)save_label = open("int_to_word_out.pickle","wb")pickle.dump(label, save_label)save_label.close()培训图像有助于将可识别的模式存储在指定的文件夹中.
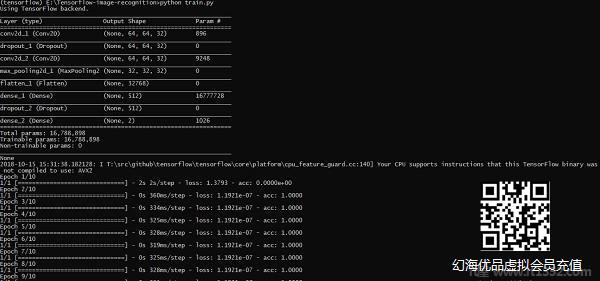
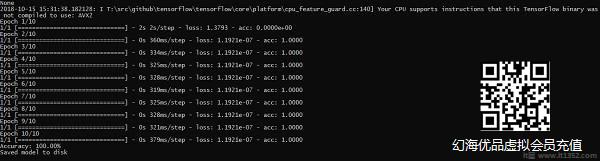
import numpyimport matplotlib.pyplot as pltfrom keras.layers import Dropoutfrom keras.layers import Flattenfrom keras.constraints import maxnormfrom keras.optimizers import SGDfrom keras.layers import Conv2Dfrom keras.layers.convolutional import MaxPooling2Dfrom keras.utils import np_utilsfrom keras import backend as Kimport load_datafrom keras.models import Sequentialfrom keras.layers import Denseimport kerasK.set_image_dim_ordering('tf')# fix random seed for reproducibilityseed = 7numpy.random.seed(seed)# load data(X_train,y_train) = load_data.data_set# normalize inputs from 0-255 to 0.0-1.0X_train = X_train.astype('float32')#X_test = X_test.astype('float32')X_train = X_train / 255.0#X_test = X_test / 255.0# one hot encode outputsy_train = np_utils.to_categorical(y_train)#y_test = np_utils.to_categorical(y_test)num_classes = y_train.shape[1]# Create the modelmodel = Sequential()model.add(Conv2D(32, (3, 3), input_shape = (64, 64, 3), padding = 'same', activation = 'relu', kernel_constraint = maxnorm(3)))model.add(Dropout(0.2))model.add(Conv2D(32, (3, 3), activation = 'relu', padding = 'same', kernel_constraint = maxnorm(3)))model.add(MaxPooling2D(pool_size = (2, 2)))model.add(Flatten())model.add(Dense(512, activation = 'relu', kernel_constraint = maxnorm(3)))model.add(Dropout(0.5))model.add(Dense(num_classes, activation = 'softmax'))# Compile modelepochs = 10lrate = 0.01decay = lrate/epochssgd = SGD(lr = lrate, momentum = 0.9, decay = decay, nesterov = False)model.compile(loss = 'categorical_crossentropy', optimizer = sgd, metrics = ['accuracy'])print(model.summary())#callbacks = [keras.callbacks.EarlyStopping( monitor = 'val_loss', min_delta = 0, patience = 0, verbose = 0, mode = 'auto')]callbacks = [keras.callbacks.TensorBoard(log_dir='./logs', histogram_freq = 0, batch_size = 32, write_graph = True, write_grads = False, write_images = True, embeddings_freq = 0, embeddings_layer_names = None, embeddings_metadata = None)]# Fit the modelmodel.fit(X_train, y_train, epochs = epochs, batch_size = 32,shuffle = True,callbacks = callbacks)# Final evaluation of the modelscores = model.evaluate(X_train, y_train, verbose = 0)print("Accuracy: %.2f%%" % (scores[1]*100))# serialize model to JSONxmodel_json = model.to_json()with open("model_face.json", "w") as json_file: json_file.write(model_json)# serialize weights to HDF5model.save_weights("model_face.h5")print("Saved model to disk")上面的代码行生成如下所示的输出 :