在本章中,我们将了解预测在敏捷数据科学中的作用.交互式报告揭示了数据的不同方面.预测形成敏捷冲刺的第四层.
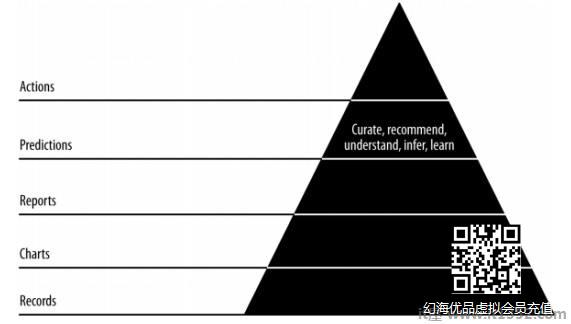
在进行预测时,我们总是参考过去的数据并将其用作未来迭代的推论.在这个完整的过程中,我们将数据从批处理历史数据转换为有关未来的实时数据.
预测的作用包括以下 :
预测有助于预测.一些预测基于统计推断.一些预测是基于权威人士的意见.
统计推断涉及各种预测.
有时预测是准确的,有时候预测是不准确的.
Predictive Analytics
预测分析包括预测建模,机器学习和数据挖掘等各种统计技术,分析当前和历史事实,对未来和未知事件进行预测.
预测分析需要培训数据.训练有素的数据包括独立和相关的功能.依赖特征是用户试图预测的值.独立特征是描述我们想要根据依赖特征预测的事物的特征.
特征研究称为特征工程;这对于做出预测至关重要.数据可视化和探索性数据分析是特征工程的一部分;这些构成了敏捷数据科学的核心.
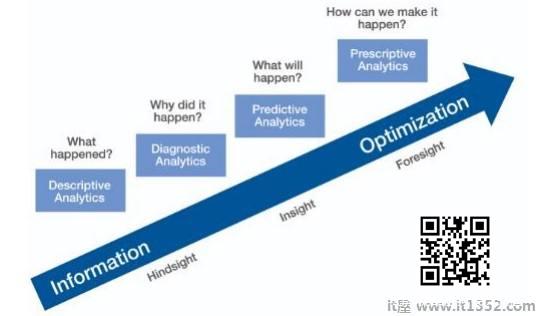
进行预测
有两种方法可以在敏捷数据科学中进行预测和减去;
回归
分类
完全建立回归或分类取决于业务需求及其分析.连续变量的预测导致回归模型和分类变量的预测导致分类模型.
回归
回归考虑包含特征的示例,从而,产生数字输出.
分类
分类接受输入并产生分类分类.
注意 : 定义统计预测输入并使机器学习的示例数据集称为"训练数据".