可以通过生成对应于模式的类或使用解析器库将Avro模式读入程序.本章介绍如何使用Avr读取模式生成类和序列化数据.
通过生成类进行序列化
要使用Avro序列化数据,请按照步骤操作如下所示 :
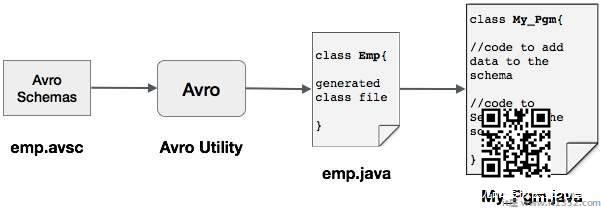
编写Avro架构.
使用Avro实用程序编译架构.您将获得与该
架构对应的Java代码.使用数据填充架构.
使用Avro库对其进行序列化.
定义架构
假设您需要一个包含以下详细信息和架构的架构;
| Field | 姓名 | id | 年龄 | 薪水 | 地址 |
| 类型 | String | int | int | int | string |
创建一个Avro架构,如下所示.
将其保存为 emp.avsc .
{ "namespace": "it1352.com", "type": "record", "name": "emp", "fields": [ {"name": "name", "type": "string"}, {"name": "id", "type": "int"}, {"name": "salary", "type": "int"}, {"name": "age", "type": "int"}, {"name": "address", "type": "string"} ]}编译架构
创建Avro架构后,需要编译使用Avro工具创建的模式. avro-tools-1.7.7.jar 是包含工具的jar.
编译Avro架构的语法
java -jarcompile schema
打开主文件夹中的终端.
创建一个新目录以使用Avro,如下所示 :
$ mkdir Avro_Work
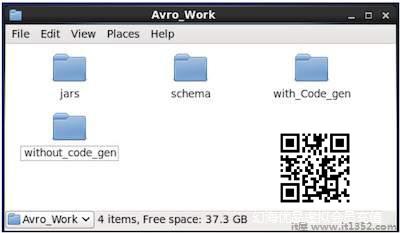
在新创建的目录中,创建三个子目录 :
首先命名架构,放置架构.
第二个名为 with_code_gen,以放置生成的代码.
第三个名为 jars,放置jar文件.
$ mkdir schema $ mkdir with_code_gen $ mkdir jars
以下屏幕截图显示了 Avro_work 文件夹的方式应该在创建所有目录后看起来.
现在/home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar 是目录wh的路径你下载了avro-tools-1.7.7.jar文件.
/home/Hadoop/Avro_work/schema/是存储架构文件emp.avsc的目录的路径.
/home/Hadoop/Avro_work/with_code_gen 是您希望存储生成的类文件的目录.
现在编译模式如下所示 :
$ java -jar /home/Hadoop/Avro_work/jars/avro-tools-1.7.7.jar compile schema /home/Hadoop/Avro_work/schema/emp.avsc /home/Hadoop/Avro/with_code_gen
编译后,在
目标目录中创建根据模式名称空间的包.在此包中,将创建具有模式名称的Java源代码.这个生成的源代码是给定模式的Java代码,可以直接在应用程序中使用.
例如,在这个例子中,一个包/文件夹,名为 it1352创建了包含另一个名为com的文件夹(因为名称空间是it1352.com),在其中,您可以观察生成的文件 emp.java .以下快照显示 emp.java :
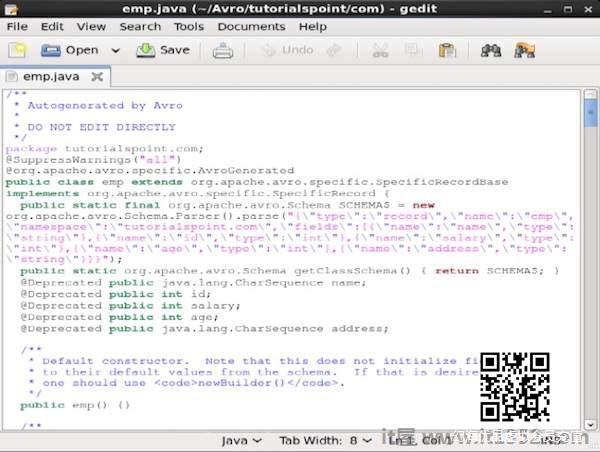
此类对于创建数据非常有用架构.
生成的类包含 :
默认构造函数和参数化构造函数接受模式的所有变量.
模式中所有变量的setter和getter方法.
Get()方法返回模式.
构建器方法.
创建和序列化数据
首先,将生成的java项目中使用的生成的java文件复制到当前目录中,或者从它所在的位置导入它.
现在我们可以编写一个新的Java文件并实例化该类.生成的文件( emp )将员工数据添加到架构中.
让我们看看使用apache Avro根据架构创建数据的过程.
第1步
Instanti吃了生成的 emp 类.
emp e1 = new emp();
步骤2
使用setter方法,插入第一个员工的数据.例如,我们创建了名为Omar的员工的详细信息.
e1.setName("omar"); e1.setAge(21); e1.setSalary(30000); e1.setAddress("Hyderabad"); e1.setId(001);同样,使用setter方法填写所有员工详细信息.
第3步
使用 SpecificDatumWriter 类创建 DatumWriter 接口的对象.这会将Java对象转换为内存中的序列化格式.以下示例为 emp 类实例化 SpecificDatumWriter 类对象.
DatumWriter< emp> empDatumWriter = new SpecificDatumWriter< emp>(emp.class);
步骤4
为 emp 类实例化 DataFileWriter .此类将符合模式的数据的序列化序列化记录与模式本身一起写入文件中.此类需要 DatumWriter 对象,作为构造函数的参数.
DataFileWriter< emp> empFileWriter = new DataFileWriter< emp>(empDatumWriter);
步骤5
使用 create打开一个新文件以存储与给定模式匹配的数据( )方法.此方法需要架构以及要存储数据的文件的路径作为参数.
在以下示例中,使用 getSchema()
empFileWriter.create(e1.getSchema(),new File("/home/Hadoop/Avro/serialized_file/emp.avro"));步骤6
使用 append()将所有创建的记录添加到文件中方法如下所示 :
empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3);
示例 - 通过生成类进行序列化
以下完整的程序显示了如何使用Apache将数据序列化到文件中Avro :
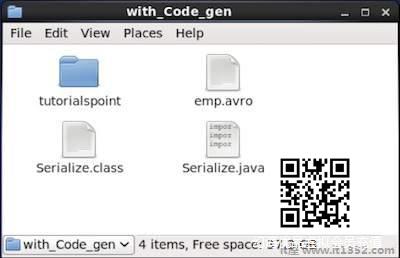
import java.io.File;import java.io.IOException;import org.apache.avro.file.DataFileWriter;import org.apache.avro.io.DatumWriter;import org.apache.avro.specific.SpecificDatumWriter;public class Serialize { public static void main(String args[]) throws IOException{ //Instantiating generated emp class emp e1=new emp(); //Creating values according the schema e1.setName("omar"); e1.setAge(21); e1.setSalary(30000); e1.setAddress("Hyderabad"); e1.setId(001); emp e2=new emp(); e2.setName("ram"); e2.setAge(30); e2.setSalary(40000); e2.setAddress("Hyderabad"); e2.setId(002); emp e3=new emp(); e3.setName("robbin"); e3.setAge(25); e3.setSalary(35000); e3.setAddress("Hyderabad"); e3.setId(003); //Instantiate DatumWriter class DatumWriter empDatumWriter = new SpecificDatumWriter(emp.class); DataFileWriter empFileWriter = new DataFileWriter(empDatumWriter); empFileWriter.create(e1.getSchema(), new File("/home/Hadoop/Avro_Work/with_code_gen/emp.avro")); empFileWriter.append(e1); empFileWriter.append(e2); empFileWriter.append(e3); empFileWriter.close(); System.out.println("data successfully serialized"); }} 浏览生成代码的目录.在这种情况下,在 home/Hadoop/Avro_work/with_code_gen .
在终端:
$ cd home/Hadoop/Avro_work/with_code_gen/
在GUI :
现在复制并保存上述程序名为 Serialize.java
的文件
编译并执行如下所示 :
$ javac Serialize.java$ java Serialize
输出
数据成功序列化
如果验证程序中给出的路径,则可以找到生成的序列化文件,如下所示.