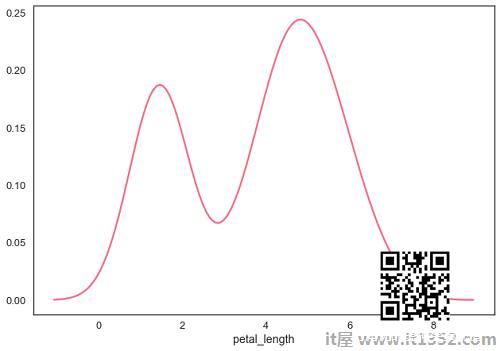
核密度估计(KDE)是一种估计连续随机变量的概率密度函数的方法.它用于非参数分析.
在 distplot 中将 hist 标志设置为False将产生核密度估计图.
示例
import pandas as pdimport seaborn as sbfrom matplotlib import pyplot as pltdf = sb.load_dataset('iris')sb.distplot(df['petal_length'],hist=False)plt.show()输出
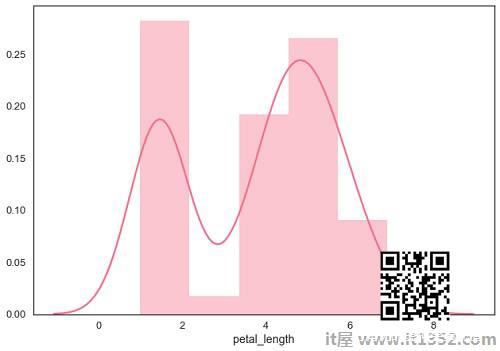
拟合参数分布
distplot()用于可视化数据集的参数分布.
示例
import pandas as pdimport seaborn as sbfrom matplotlib import pyplot as pltdf = sb.load_dataset('iris')sb.distplot(df['petal_length'])plt.show()输出
绘制双变量分布
双变量分布用于确定两个变量之间的关系.这主要处理两个变量之间的关系以及一个变量相对于另一个变量的行为.
分析seaborn中的双变量分布的最佳方法是使用 jointplot() 功能.
Jointplot创建一个多面板图形,用于投影两个变量之间的双变量关系,以及每个变量在不同轴上的单变量分布.
散点图
散点图是可视化分布的最便捷方式,其中每个观测值通过x轴和y轴在二维图中表示.
示例
import pandas as pdimport seaborn as sbfrom matplotlib import pyplot as pltdf = sb.load_dataset('iris')sb.jointplot(x = 'petal_length',y = 'petal_width',data = df)plt.show()输出
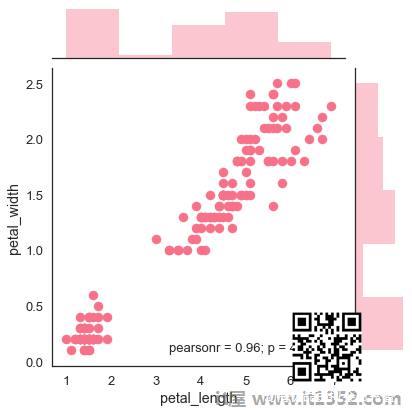
上图显示了Iris数据中 petal_length 和 petal_width 之间的关系.图中的趋势表明,研究中的变量之间存在正相关.
Hexbin Plot
六角形分级用于双变量数据分析时数据密度稀疏,即数据非常分散且难以通过散点图进行分析.
一个名为'kind'的附加参数和值'hex'绘制了hexbin图.
示例
import pandas as pdimport seaborn as sbfrom matplotlib import pyplot as pltdf = sb.load_dataset('iris')sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')plt.show()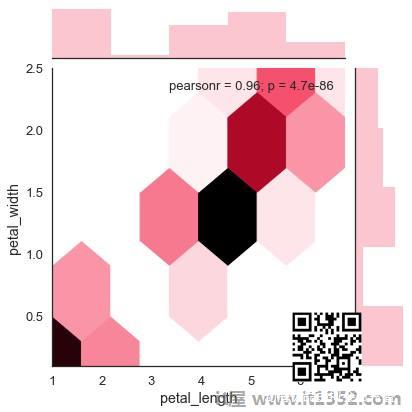
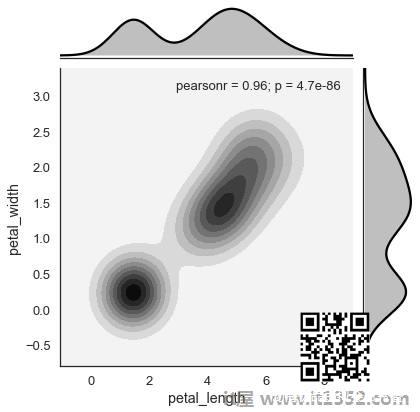
核密度估计
核密度估计是一种估计变量分布的非参数方法.在seaborn中,我们可以使用 jointplot()绘制kde.
将值'kde'传递给参数种类以绘制内核图.
示例
import pandas as pdimport seaborn as sbfrom matplotlib import pyplot as pltdf = sb.load_dataset('iris')sb.jointplot(x = 'petal_length',y = 'petal_width',data = df,kind = 'hex')plt.show()